bahmanm
Husband, father, kabab lover, history buff, chess fan and software engineer. Believes creating software must resemble art: intuitive creation and joyful discovery.
Views are my own.
- 21 Posts
- 22 Comments

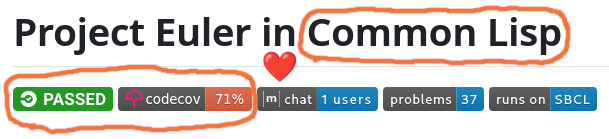
“Announcment”
It used to be quite common on mailing lists to categorise/tag threads by using subject prefixes such as “ANN”, “HELP”, “BUG” and “RESOLVED”.
It’s just an old habit but I feel my messages/posts lack some clarity if I don’t do it 😅

 1·1 year ago
1·1 year agoI usually capture all my development-time “automation” in Make and Ansible files. I also use makefiles to provide a consisent set of commands for the CI/CD pipelines to work w/ in case different projects use different build tools. That way CI/CD only needs to know about
make build,make test,make package, … instead of Gradle/Maven/… specific commands.Most of the times, the makefiles are quite simple and don’t need much comments. However, there are times that’s not the case and hence the need to write a line of comment on particular targets and variables.
Can you provide what you mean by check the environment, and why you’d need to do that before anything else?
One recent example is a makefile (in a subproject), w/ a dozen of targets to provision machines and run Ansible playbooks. Almost all the targets need at least a few variables to be set. Additionally, I needed any fresh invocation to clean the “build” directory before starting the work.
At first, I tried capturing those variables w/ a bunch of
ifeqs,shells anddefines. However, I wasn’t satisfied w/ the results for a couple of reasons:- Subjectively speaking, it didn’t turn out as nice and easy-to-read as I wanted it to.
- I had to replicate my (admittedly simple)
cleantarget as a shell command at the top of the file.
Then I tried capturing that in a target using
bmakelib.error-if-blankandbmakelib.default-if-blankas below.############## .PHONY : ensure-variables ensure-variables : bmakelib.error-if-blank( VAR1 VAR2 ) ensure-variables : bmakelib.default-if-blank( VAR3,foo ) ############## .PHONY : ansible.run-playbook1 ansible.run-playbook1 : ensure-variables cleanup-residue | $(ansible.venv) ansible.run-playbook1 : ... ############## .PHONY : ansible.run-playbook2 ansible.run-playbook2 : ensure-variables cleanup-residue | $(ansible.venv) ansible.run-playbook2 : ... ##############But this was not DRY as I had to repeat myself.
That’s why I thought there may be a better way of doing this which led me to the manual and then the method I describe in the post.
running specific targets or rules unconditionally can lead to trouble later as your Makefile grows up
That is true! My concern is that when the number of targets which don’t need that initialisation grows I may have to rethink my approach.
I’ll keep this thread posted of how this pans out as the makefile scales.
Even though I’ve been writing GNU Makefiles for decades, I still am learning new stuff constantly, so if someone has better, different ways, I’m certainly up for studying them.
Love the attitude! I’m on the same boat. I could have just kept doing what I already knew but I thought a bit of manual reading is going to be well worth it.
That’s a great starting point - and a good read anyways!
Thanks 🙏
Agree w/ you re trust.
Thanks. At least I’ve got a few clues to look for when auditing such code.
I couldn’t agree more 😂
Except that, what the author uses is pretty much standard in the Go ecosystem, which is, yes, a shame.
To my knowledge, the only framework which does it quite seamlessly is Spring Boot which, w/ sane and well thought out defaults, gets the tracing done w/o the programmer writing a single line of code to do tracing-related tasks.
That said, even Spring’s solution is pretty heavy-weight compared to what comes OOTB w/ BEAM.
I got to admit that your point about the presentation skills of the author are all correct! Perhaps the reason that I was able to relate to the material and ignore those flaws was that it’s a topic that I’ve been actively struggling w/ in the past few years 😅
That said, I’m still happy that this wasn’t a YouTube video or we’d be having this conversation in the comments section (if ever!) 😂
To your point and @krnpnk@feddit.de’s RE embedded systems:
That’s absolutely true that such a mindset is probably not going to work in an embedded environment. The author, w/o explicitly mentioning it anywhere, is explicitly talking about distributed systems where you’ve got plenty of resources, stable network connectivity and a log/trace ingestion solution (like Sumo or Datadog) alongside your setup.
That’s indeed an expensive setup, esp for embedded software.
The narrow scope and the stylistic problem aside, I believe the author’s view is correct, if a bit radical.
One of major pain points of troubleshooting distributed systems is sifting through the logs produced by different services and teams w/ different takes of what are the important bits of information in a log message.It get extremely hairy when you’ve got a non-linear lifeline for a request (ie branches of execution.) And even worse when you need to keep your logs free of any type of information which could potentially identify a customer.
The article and the conversation here got me thinking that may be a combo of tracing and structured logging can help simplify investigations.
Thanks for sharing your insights.
Thinking out loud here…
In my experience with traditional logging and distributed systems, timestamps and request IDs do store the information required to partially reconstruct a timeline:
- In the case of a linear (single branch) timeline you can always “query” by a request ID and order by the timestamps and that’s pretty much what tracing will do too.
- Things, however, get complicated when you’ve a timeline w/ multiple branches.
For example, consider the following relatively simple diagram.
Reconstructing the causality and join/fork relations between the executions nodes is almost impossible using traditional logs whereas a tracing solution will turn this into a nice visual w/ all the spans and sub-spans.

That said, logs do shine when things go wrong; when you start your investigation by using a stacktrace in the logs as a clue. That (stacktrace) is something that I’m not sure a tracing solution will be able to provide.
they should complement each other
Yes! You nailed it 💯
Logs are indispensable for troubleshooting (and potentially nothing else) while tracers are great for, well, tracing the data/request throughout the system and analyse the mutations.
I’m not sure how this got cross-posted! I most certainly didn’t do it 🤷♂️
I think I understand where RMS was coming from RE “recursive variables”. As I wrote in my blog:
Recursive variables are quite powerful as they introduce a pinch of imperative programming into the otherwise totally declarative nature of a Makefile.
They extend the capabilities of Make quite substantially. But like any other powerful tool, one needs to use them sparsely and responsibly or end up w/ a complex and hard to debug Makefile.
In my experience, most of the times I can avoid using recursive variables and instead lay out the rules and prerequisites in a way that does the same. However, occasionally, I’d have to resort to them and I’m thankful that RMS didn’t win and they exist in GNU Make today 😅 IMO purist solutions have a tendency to turn out impractical.
Uh, I’m not sure I understand what you mean.
I just quote my comment on a similar post earlier 😅
A bit too long for my brain but nonetheless it is written in plain English, conveys the message very clearly and is definitely a very good read on the topic. Thanks for sharing.
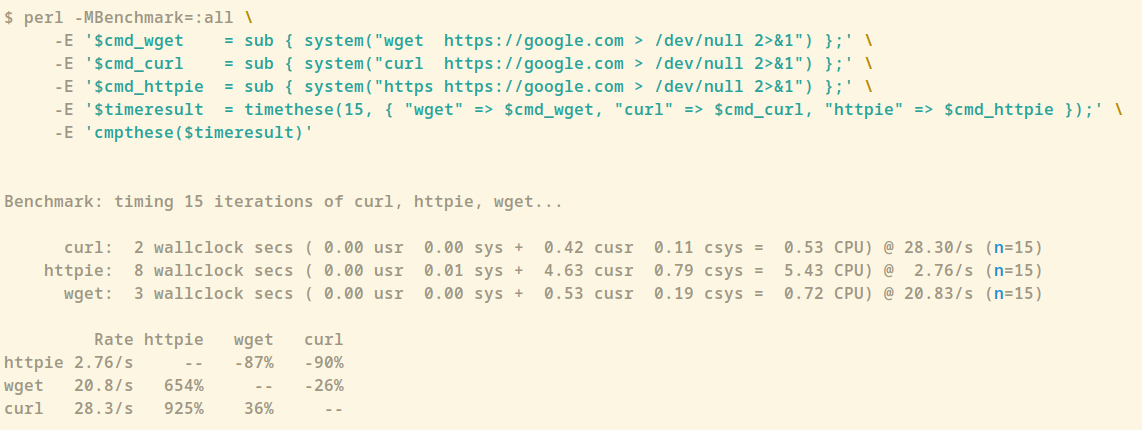
Now that I know which endpoints I’m interested in and which arguments I need to pass, exporting them to Prometheus is my next step. Though I wasn’t sure where to begin w/ - I was thinking about writing the HTTP requests in Java or Python and export the results from there.
Blackbox exporter is definitely easier and cleaner. Thanks for the tip 💯
I wonder why all the down-votes!? The linked article was a good read IMO. What did I miss here?
Good point 👍
Likewise, I never thought I’d need any timestamp w/ a finer resolution than millis, until my tests started failing:
There is a feature in bmakelib (called
!!logged) which logs the stdout/err of a given target to disk. When I was writing tests for it, I noticed that occasionally my tests fail where they shouldn’t have (for context, the tests used to create files w/ millis resolution and then check the contents.) Turned out the my tests were fast enough that more than 1 of them would run and finish in a single millisecond causing the “expected” files to be overwritten.That’s how I got to thinking that it may be something which can be added to bmakelib.
The benefit is that you don’t need to do much and you ensure the timestamp has a high resolution. That will make it harder to produce difficult-to-debug bugs 😅
The downsides are 1) cognitive load (yet another thing to know about) 2) filenames/variables/… will have 3 extra characters which stand for µ fraction.
Does that make sense?


{kind=link}
{kind=link}
{kind=link}
{kind=link}
I’m not impressed. Talk is cheap, show me the code.
 11·1 year ago
11·1 year ago“Azure”…“secure”. Interesting 😆
 3·1 year ago
3·1 year agoEffective method…so long as your kid doesn’t hate you 😂 in which case, IMHO, it should be a favourite aunt/uncle/teacher/… who introduces them to the topic while the parents try to stay quite on the topic as much as possible.
Thanks for the pointer! Very interesting. I actually may end up doing a prototype and see how far I can get.